
Aduna AutoFocus 2004.2
Discuss your AutoFocus questions about hot tub filters reviews and remarks in the freely accessible forum.
Your Desktop Exploration Tool
Aduna AutoFocus helps you to search and find information on your PC, network disks, mail boxes, websites and Aduna Metadata Server sources. It scans all places where you expect valuable information and provides powerful means for retrieving that information.
AutoFocus is based on Guided Exploration which gives you information with high precision. Take a guided tour to learn more about AutoFocus.
AutoFocus is free for private use. See the License for more info on commercial and other use.
Subscribe to the Aduna Newsletter to receive periodic AutoFocus updates and announcements.
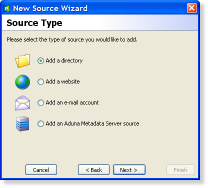
Define your information sources…
With AutoFocus you can search and explore the following types of information sources:
Directories
Websites
E-mail accounts (IMAP)
Aduna Metadata Server sources
At any time you can add or edit the set of information sources used by AutoFocus. These sources are scanned so that AutoFocus can generate instant results for your searches. After scanning you are able to search in and explore your sources with powerful retrieval tools.
AutoFocus supports all major file formats, including MS Office (Word, Excel, PowerPoint), OpenOffice (Writer, Impress, Calc, Draw), PDF, HTML, RTF, etc.
… and start finding information!
AutoFocus lets you interact with your information in multiple ways:
Metadata facets
Document metadata contains information about your documents, such as location, date, author, size, etc. You can use this metadata to find or refine what you are looking for. Combine metadata facets to find, for example, PDF documents written by a certain author in a certain period of time.
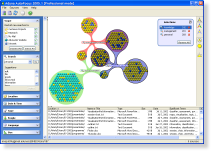
Cluster Maps
Results are shown in a Cluster Map. The map shows you how information is related to your search terms. In the example at the right three search terms are used. The map shows documents as yellow nodes, web pages as green nodes and e-mails as blue nodes. Click on the map to view it at its normal size.
Suggestions
AutoFocus helps you to decide what you are looking for. Suppose you look for PDF documents written by a specific author. AutoFocus gives you a list of author names and file types it has detected in your sources. Just click on their names to visualize them in the Cluster Map.
When you select document clusters in the Cluster Map, AutoFocus presents you a list of suggested keyword searches for refinement. This automatically generated list helps you to find unexpected information.
Using Aduna AutoFocus
People value the power of AutoFocus in two ways.
First they use it as an advanced search tool on their desktop. Facets, Cluster Maps and Suggestions enable quick drill down to the information wanted.
Next to that users value the way in which AutoFocus enables them to freely explore their information sources. You often find unexpected information by browsing the facets, analysing the Cluster Maps or using the suggestions.
AutoFocus : FAQ
Do you have a question not listed in the FAQ? Tell us about it!
Table of Contents
- Is AutoFocus a local search engine?
- What are suggestions and significant terms?
- Which file formats does AutoFocus handle?
- How many documents can AutoFocus handle?
- Can AutoFocus connect to proprietary systems (e.g. databases)?
- Can AutoFocus be extended to support file format XYZ?
- Is AutoFocus suitable for use in an organisation?
Is AutoFocus a local search engine?
It may look like one and can certainly be used as one, but there is more compared to existing search applications:
Metadata facets: AutoFocus lets you search using keywords, phrases, wildcards, etc., but you can also use other facets of your information, like date and author to specify what you are looking for.
Choose, don’t type: most facets show you a list or tree of occurring values. E.g., the People facet lists all names occurring in your sources as document author or sender or receiver of an email. It is generally easier to recognize the value you want than to correctly type it in yourselves.
Overview: it presents the results in such a way that it gives you a comprehensive overview of the available information.
Assistance: You have more than one way to refine your query: by entering another search term, by selecting other metadata facet values, by choosing a term from the search suggestions, or by picking a significant term in the results list.
What are suggestions and significant terms?
Significant terms are terms occurring in the document text that according to AutoFocus best describe the main topics of the document. A mix of statistical measures is used to come up with the 10 most descriptive terms for every document.
These significant terms are displayed as part of the document info when the user selects documents in the Cluster Map. They appear as a column in the table view or as a line of text links in the text view.
Not only do these terms give a good first impression about the document’s content, they can also immediately be used as search terms by clicking on them.
Whenever the user selects a set of documents, AutoFocus also shows representative terms for this set. These terms are shown as Suggestions in the Search panel at the left, in alphabetical order.
Which file formats does AutoFocus handle?
AutoFocus 2004.2 knows how to process ASCII files (.txt), website formats (.html, .xml), Adobe Acrobat files (.pdf), Microsoft Office files (.doc, .xls, .ppt), Microsoft Works files (.wks), OpenOffice files (.sx), StarOffice files (.sd, .sx), OpenDocument files (.od), WordPerfect files and Rich Text Format files (*.rtf).
Technically this means that AutoFocus knows how to extract the text and optionally additional metadata like titles and authors from these file formats. Still, AutoFocus always takes all files into account, regardless of format, and you can always access them through facets like location, size and date.
AutoFocus uses several heuristics to determine a file’s format. Therefore, it is often not necessary for a file to have the mentioned file extension in order to be scanned correctly.
How many documents can AutoFocus handle?
Easily (on low cost hardware) up to tens of thousands of documents.
Please note that the initial scanning of that many files will take up some time. Subsequent scans only take the changed files into account and are generally much faster.
Can AutoFocus connect to proprietary systems (e.g. databases)?
Yes, with modest modifications AutoFocus enables you to search other data sources such as databases or document management systems. Contact the Aduna team for more information about the connection to other proprietary data sources.
Can AutoFocus be extended to support file format XYZ?
AutoFocus can also be extended, sometimes only with modest modifications (depending on the file type at hand), to support other file formats. Contact us for more information.
Is AutoFocus suitable for use in an organisation?
AutoFocus can connect to Aduna Metadata Servers. This server scans documents available on a shared network drive or intranet. This way, individual AutoFocus users do not have to define and scan those sources, they can immediately search the information using this service, saving effort, network bandwidth and computational costs.
Metadata Server
Metadata = valuable!
Metadata is information about information, for example the author of a document or its publication date. Metadata is helpful when you want to find or explore information. It helps you to see what information is there, to decide whether it is of value to you and where to go next. Metadata saves you time in finding the right information.
We are currently in the last phase of completing the Metadata Server release. Subscribe to the Aduna Newsletter to get notified about the final release.
Automated metadata extraction
The Aduna Metadata Server automatically extracts metadata from information sources, like a file server, an intranet or public web sites.
The stored metadata is available for tools such as Aduna AutoFocus and Aduna Spectacle. These tools enable the user to find and explore information by using the extracted metadata.
Up in short time
The Aduna Metadata Server is a powerful and scalable store for metadata. It works out-of-the-box. Just install the server, use the adminstration pages to define the information sources to be scanned and schedule the scanning process.
Using Aduna Metadata Server
With Aduna AutoFocus and Aduna Spectacle you can access the Metadata Server. The different metadata facets are offered to the user by these tools as a selection mechanism for further refinement or exploration. They enable cross-facet questions like: 'Give me all PDF’s (value of type facet) that I (value of people facet) made yesterday (value of time facet) with the word ‘project X’ in it (value of keyword facet).
Open standard for metadata
The Metadata Server is based on Sesame, an open source RDF-based storage framework. Read more about Sesame at http://openrdf.org. RDF is an open W3C standard for description of metadata.
You can write your own applications that make use of the Aduna Metadata Server. The server is accessible with standard (Sesame) protocols.
Sesame RDF Database
Sesame is a stable, high-capacity, flexible platform for storing, querying, and manipulating RDF and RDF Schema.
Originally, it was developed by Aduna (then known as Aidministrator) as a research prototype for the EU research project On-To-Knowledge. Now, it is developed and maintained by Aduna in cooperation with NLnet Foundation, developers from OntoText, and a number of volunteer developers who contribute ideas, bug reports and fixes.
The Sesame website is http://www.openrdf.org/.
Product support
Welcome to the Aduna product support page. We try to make locating support for your Aduna product quick and easy. Simply follow the links below to locate software downloads, manuals, flyers and brochures.
You may contact our Aduna Support Team at any time. For immediate assistance please call +31 33 465 9987. Or even better, use the support e-mail address: support@aduna.biz.
Software downloads
- Aduna AutoFocus
- Aduna Metadata Server
- Sesame
Manuals
- Aduna AutoFocus
- Aduna Metadata Server (coming soon)
- Sesame
Flyers & Brochures
- Aduna AutoFocus
- Aduna Metadata Server
- Aduna Spectacle (coming soon)
- Sesame
Frequently Asked Questions
- Aduna AutoFocus
- Aduna Metadata Server
- Aduna Spectacle (coming soon)
- Sesame
Services & Solutions
This section describes the kind of projects Aduna likes to participate in and gives you an overview of the available expertise in the Aduna team.
Next to being highly qualified software developers, the Aduna team members are also experienced consultants. We have worked for large and small companies, using our own software and that of others. The binding factor over all project-related work is the customer’s wish to improve the interaction with information. We improved the actual interaction by delivering new user interfaces, but we also indirectly improved the finding of information through data integration projects.
Below you find a list of interesting work fields that belong to our expertise. Please feel free to inquire and contact us about possible projects. Also have a look at our Clients page for descriptions of past and ongoing projects.
Product Integration
The Aduna team provides services for Aduna AutoFocus, Aduna Metadata Server and Aduna Spectacle. Customers especially value our experience with the integration of these software products in existing infrastructures. We can help you to decide whether you can use existing tools out-of-the-box or whether small modifications to our products are necessary to solve your problems.
Data Integration Projects
Sesame, the open source RDF framework, provides an ideal platform for integration of separate, heterogeneous information sources. The goal of this integration is to improve browsing or searching multiple information sources transparently. Sesame works as a Semantic Web front-end for all questions.
One of the good things about Sesame is that it is free. Everybody can use it! More specifically, Sesame is available under an Open Source license, giving you a wide range of opportunities for taking control over the integration process. Experts from Aduna are available to help you with this integration.
E-commerce Shop Navigation
Metadata can be used to succesfully guide web shop visitors to products of their need, increasing the web shop’s revenues. Aduna has hands-on experience with building web shops and we can advise you how to design your own shop. Did you know that metadata faceted browsing is the way to go for your web shop? Let us explain why: this helps to guide people to the right products, to never sell “no”, to never show too much. In short: to make your web shop profitable!
Metadata Projects
Taxonomies, controlled vocabularies, thesauri: these words often trigger knowledge managers responsible for information disclosure in their organisation. In metadata projects organisations try to build references (‘words that refer to some piece of information’) to useful information.
The Aduna team has experience with these lightweight ontologies and can advice you on topics like taxonomy maintenance, the connection of a lightweight ontology to information sources and ontology-based navigation.
Information Visualisation
Aduna AutoFocus is based on information visualisation. It shows how information items are related to metadata facets. We like to share our knowledge of information visualisation with you. With our help we can show you the possibilities (and pitfalls!) of visualisation. We are happy to bring our own software, but we can also work with that of other parties.
Portfolio
The following organizations and/or websites are powered by Aduna:
Guided Exploration™
Vacances-scolaires.com
Vacances-scolaires.com - one of the largest online travel agencies in France - uses Guided Exploration™ to allow buyers to find their perfect holiday destination. Read more…
Hink Intersport Megastores
The Hink Intersport Megastores uses Guided Exploration™ to show potential buyers all products available in the physical Intersport MegaStores.
HOGBR Kennisontsluiter
The Hoger Onderwijs Groep Bouw en Ruimte - an initiative of the building and construction faculties of several dutch universities - is currently evaluating Aduna’s Guided Exploration™ for use in the educational programmes offered by said universities. [intranet site]
Bouwradius Informatiemonitor®
Bouwradius - one of the largest providers in the Netherlands of educational services in the building and construction domain - uses Guided Exploration™ to guide its employees to the latest innovations published in relevant media. [intranet site]
AutoFocus™ Server
Town of Coevorden
The town of Coevorden uses AutoFocus™ server to power its website’s search functionality. Using AutoFocus, visitors looking for information are guided to the information most relevant to their initial query.
Sesame RDF database
Elsevier Science
Aduna provides Semantic Web and information visualisation expertise and software to DOPE - Drug Ontology Project for Elsevier - in the form of Sesame and the Spectacle ClusterMap library.
At A Glance
Aduna is a privately owned company focused on turning dumb searching into smart finding by creating software based on open standards that implements the concept of Guided Exploration?. Guided Exploration allows you to stop wasting time on organizing and archiving your information and stop wasting time searching for your information. It cuts both ways. So Guided Exploration saves time and money, and allows you to make smarter decisions, increase ecommerce sales, keep and grow your intellectual capital, and implode project schedules and budgets. Effortlessly and affordable.
Our passion is to enable individuals and businesses throughout the world to thrive on their collective intelligence and enable people to do new things by creating versatile, human-centered software. We focus on letting you work smarter, not harder. We make software that makes you smart.
Open Standards Only–Freedom of Choice
We’re working hard to spark and lead the emerging semantic web by delivering extreme quality open software systems (applications, platform, server software, tool kits, services and technology) for end users, business engineers, enterprise developers and embedded software developers.
Inspired by Bill Joy’s law “Innovation happens elsewhere” and the business value of open standards, we make sure that all our products are developed using open standards only.
The Java platform is used for all software and delivers stunning performance. W3C standards and upcoming technologies like XML, RDF/S, DAML+OIL, OWL, RQL, RDQL, and SeRQL are used for data and knowledge definitions and protocols. JXTA peer-to-peer protocols form the basis for the emerging SWAP (Semantic Web And Peer-to-peer) initiatives. APIs (Application Programmer Interfaces) are specified and published conform to industry standards (javadoc), enabling others to innovate on top of Aduna’s products and technology and deploy it on the platform of choice.
Administration
Aduna’s staff includes some of the most experienced technology professionals on semantic web technology, knowledge and software engineering and is backed by Meridian Holding venture capital. Aduna currently has 9 employees.
The Team
Jos van der Meer, Founder
Wil van der Meer, Founder
Jeroen Wester, Senior Managing Consultant
Jeen Broekstra, Knowledge Engineer
Christiaan Fluit, Lead Engineer, Visualization
Herko ter Horst, Senior Developer
Arjohn Kampman, Senior Developer
Hilde Bleeker, Controller
Innovation on a Scientific Bedrock
Professor Frank van Harmelen from the Vrije Universiteit in our Science Board plays a pivotal role between our business and the emerging semantic web technology standards. Frank van Harmelen connects the scientific world, W3C and the business world, causing us to quickly adopt new standards as well as setting them. SeRQL, for instance, is developed by Aduna and quickly gains acceptance in the semantic web community led by Tim Berners-Lee as preferred query language.
Innovation & Development is Aduna’s heart and soul. It is our source of disruptive innovation. Building, keeping and growing a sharp and focused team creating the next generation semantic web technology is hard to do and it is our core, our reason of existence. We regularly have students from different universities for a practical period, and temporary additional consultants for particular needs (e.g. market research, business strategy definition, etc.). and the Semantic Web community led by Tim Berners-Lee. We are primarily driven and motivated by high-quality technology and people, and realistic modesty without any concession to high ambition levels.
Location
The inspiring center of Amersfoort forms the basis for all our efforts. Directions to our office:
Prinses Julianaplein 14 b
3817 CS Amersfoort
The Netherlands
Phone: +31 33 465 9987
Fax: +31 33 465 9987
Email: info@aduna.biz
Web: aduna.biz
Differentiation by Guided Exploration
Spectacle’s Guided Exploration raises the standard for finding information to the next level. Spectacle trivializes the engines used by companies like Amazon. Aduna aims to provide the default finding engine, globally. Now everyone can set up their own Amazon-like shop, either on the internet or in the enterprise in just a couple of weeks due to a number of key implementation characteristics that allow for effortless mass customization:
Versatility: applicable to any domain, from retail to parts manufacturers, from knowledge management to ecommerce;
Performance: scales to millions of objects with thousands of facets each and hundreds of thousands of simultaneous users, with a customized view for every individual user;
Evolvability: new demands driven by marketing and sales can be realized in a day, or two.
Affordability: Pay-for-use based licensing, short time to service (days or weeks, rather than months), and low-cost hardware add to your bottom line.
Business Model
Aduna generates revenue through two programs: selling and licensing software products and professional services & training.
Products & Solutions
Aduna offers two high-performing products: AutoFocus and Spectacle Suite. The AutoFocus solution complements basic search with Guided Exploration and is built using components from Spectacle Suite.
AutoFocus Personal & AutoFocus Server
Aduna AutoFocus comes in two flavors: AutoFocus Personal and AutoFocus Server . AutoFocus Personal brings Guided Exploration in a sophisticated “humane” interface to every desktop and puts users back in control over their documents, no matter where they are. AutoFocus Server adds Guided Exploration to free text searches on web sites or intranets. Aduna AutoFocus’ Guided Exploration makes affordable, fast and precise searching (or finding, as we prefer to call it) available to everyone.
Spectacle Suite
Aduna Spectacle Suite offers a high performance, scalable, light-weight and flexible way to slice and dice this knowledge in unforeseen ways. Its like a mutual reinforcing combination of next generation data mining and search engines, and akin to the pivot tables in spreadsheets that give multi-dimensional access to distributed sources of both structured and unstructured information, yet on a much larger scale. Doing so, documents, travel destinations, used cars, electronic parts, DVDs, movies, music, job vacancies, what have you, show up at the right time and in the right context.
The following building blocks make up Spectacle Suite:
Guided Exploration Engine
Navigation engine for millions of objects, each with thousands of facets. Loads the exploration space from Sesame or directly from the original source. Advanced behavior control. Can be embedded in web services, or render pages using JSPs and servlets.
Sesame
Component for storage and querying of RDF metadata. Supports reasoning over metadata. Storage can be handled by a choice of database backends or directly in core memory, querying is supported in the expressive query language SeRQL, through a variety of access protocols (SOAP, HTTP, RMI). Serves as a hub between Bonanza and the Guided Exploration Engine, the Cluster Map Viewer and the Link Map Viewer. Find out more about Sesame at http://sesame.aduna.biz/.
Cluster Map Viewer Graphical
Component for visualization and manipulation of Venn-diagrams. Receives information from Sesame or directly from original source.
Link Map Viewer Graphical
Component for visualization and manipulation of networked graphs. Receives information from Sesame or directly from original source.
Bonanza
Manages the Diggers that crawl web sites or file systems. Hands over the raw material to a set of document-specific Sievers that extract relevant metadata. Next, this metadata is stored in Sesame.
Contact
Office:
Aduna B.V.
Prinses Julianaplein 14 b
3817 CS Amersfoort
The Netherlands
For directions click here.
Phone:
+31 33 465 99 87
E-mail:
You can also contact us using one of the following e-mail addresses:
sales@aduna.biz - sales and payment-related questions
support@aduna.biz - support questions
feedback@aduna.biz - we welcome your feedback!
info@aduna.biz - any other questions or remarks you may have
Directions
Address:
Prinses Julianaplein 14 b
3817 CS Amersfoort
The Netherlands
Phone:
+31 33 465 99 87
Amersfoort is 25 minutes east of Amsterdam and 40 minutes east of Schiphol Airport.
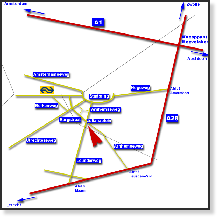
Travelling by car:
From Amsterdam/Apeldoorn/Zwolle (A1):
At junction Hoevelaken, merge onto the A28 south, toward Utrecht.
Take the Amersfoort exit (exit 8) onto Hogeweg.
Follow Hogeweg onto Stadsring.
Turn left onto Utrechtseweg, direction Utrecht.
Follow Leusderweg until the roundabout at Julianaplein.
We are at number 14 b (look for the large number 14 on the door).
From Utrecht (A28):
Take the Maarn exit (exit 5) onto Leusderweg.
Follow Leusderweg until the roundabout at Julianaplein.
We are at number 14 b (look for the large number 14 on the door).
There is limited free parking space right in front of our office. Parking meters in the direct vicinity allow for one hour parking. The best place to park is the (paid) parking garage underneath the ING Bank building at the corner of Stadsring and Arnhemseweg. Travelling by train:
Our office is on a 10 minute walking distance from Amersfoort central station:
Take a train to Amersfoort CS.
Exit onto Stationsstraat.
Cross the street and turn left.
Turn right onto Johan van Oldebarneveldtstraat.
Turn left onto Berkenweg.
Turn left onto Utrechtseweg.
Turn right just before the railway tracks (i.e., follow the railway tracks).
Turn left onto Leusderweg.
Are office is at the roundabout, we are at number 14 b (look for the large number 14 on the door).
If you prefer, there are plenty of taxi’s available at Amersfoort central station.